





While developing Machine learning models to solve Fraud detection, delivery address autocompletes, user identity detection, etc. we faced different challenges. One of the major challenges was the real-time feature generation and dynamic ML model serving in real-time at scale.
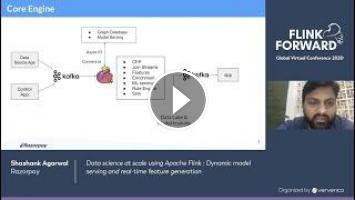
For achieving this in real-time and on the high scale we developed our Data intelligent platform "Mitra". It’s based on Kappa+ architecture where we process all data on streams. Our core engine is based on Apache Flink with Kafka as a data queue and Rocksdb as in-memory states. We use Kafka for both Data flow and as a control stream to send dynamic control signals to our platform. We have a lot of other components in our Mitra platforms like Graph DB, ML Model server, Dynamic rule engine on streams and in-memory data lake
Key features of "Mitra Platform" which developed using Apache Flink :
- Predict results within 200 milliseconds in the distributed environment
- Generate Hundreds of features on the fly during model serving
- Serve results from deployed ML models
- Dynamic rule engine on Flink streams
We heavily use Flink’s in-memory states, CEP (Complex event processing), broadcast states and Async IO to achieve this. We have more than 60 operators and 40+ in memory states in our Flink application.
For more info read this blog: https://medium.com/razorpay-unfiltered/data-science-at-scale-using-apache-flink-982cb18848b
Our platform and architecture improved a lot after this blog. It serves 500+ e-commerce companies in India in real-time.mpletes, user identity detection, etc. we faced different challenges. One of the major challenges was the realtime feature generation and dynamic ML model serving in real-time at scale.
For achieving this in real-time and on the high scale we developed our Data intelligent platform "Mitra". It’s based on Kappa+ architecture where we process all data on streams. Our core engine is based on Apache Flink with Kafka as a data queue and Rocksdb as in-memory states. We use Kafka for both Data flow and as a control stream to send dynamic control signals to our platform. We have a lot of other components in our Mitra platforms like Graph DB, ML Model server, Dynamic rule engine on streams and in-memory data lake
Key features of "Mitra Platform" which developed using Apache Flink :
- Predict results within 200 milliseconds in the distributed environment
- Generate Hundreds of features on the fly during model serving
- Serve results from deployed ML models
- Dynamic rule engine on Flink streams
We heavily use Flink’s in-memory states, CEP (Complex event processing), broadcast states and Async IO to achieve this. We have more than 60 operators and 40+ in memory states in our Flink application.
For more info read this blog : https://medium.com/razorpay-unfiltered/data-science-at-scale-using-apache-flink-982cb18848b
Our platform and architecture improved a lot after this blog. It serves 500+ e-commerce companies in India in real-time.
For achieving this in real-time and on the high scale we developed our Data intelligent platform "Mitra". It’s based on Kappa+ architecture where we process all data on streams. Our core engine is based on Apache Flink with Kafka as a data queue and Rocksdb as in-memory states. We use Kafka for both Data flow and as a control stream to send dynamic control signals to our platform. We have a lot of other components in our Mitra platforms like Graph DB, ML Model server, Dynamic rule engine on streams and in-memory data lake
Key features of "Mitra Platform" which developed using Apache Flink :
- Predict results within 200 milliseconds in the distributed environment
- Generate Hundreds of features on the fly during model serving
- Serve results from deployed ML models
- Dynamic rule engine on Flink streams
We heavily use Flink’s in-memory states, CEP (Complex event processing), broadcast states and Async IO to achieve this. We have more than 60 operators and 40+ in memory states in our Flink application.
For more info read this blog: https://medium.com/razorpay-unfiltered/data-science-at-scale-using-apache-flink-982cb18848b
Our platform and architecture improved a lot after this blog. It serves 500+ e-commerce companies in India in real-time.mpletes, user identity detection, etc. we faced different challenges. One of the major challenges was the realtime feature generation and dynamic ML model serving in real-time at scale.
For achieving this in real-time and on the high scale we developed our Data intelligent platform "Mitra". It’s based on Kappa+ architecture where we process all data on streams. Our core engine is based on Apache Flink with Kafka as a data queue and Rocksdb as in-memory states. We use Kafka for both Data flow and as a control stream to send dynamic control signals to our platform. We have a lot of other components in our Mitra platforms like Graph DB, ML Model server, Dynamic rule engine on streams and in-memory data lake
Key features of "Mitra Platform" which developed using Apache Flink :
- Predict results within 200 milliseconds in the distributed environment
- Generate Hundreds of features on the fly during model serving
- Serve results from deployed ML models
- Dynamic rule engine on Flink streams
We heavily use Flink’s in-memory states, CEP (Complex event processing), broadcast states and Async IO to achieve this. We have more than 60 operators and 40+ in memory states in our Flink application.
For more info read this blog : https://medium.com/razorpay-unfiltered/data-science-at-scale-using-apache-flink-982cb18848b
Our platform and architecture improved a lot after this blog. It serves 500+ e-commerce companies in India in real-time.
- Catégories
- E commerce Divers
Ajouter un commentaire
Up Next
Autoplay
-
30:48

Apache HBase Tutorial For Beginners | What is Apache HBase? | Big Data Training | Edureka Rewind
-
07:26
Use Cases of Pandas in Data Science | Data Science in Telugu
-
43:46
E174: The Art & Science of Real Time AI Chatbot eCommerce Price Negotiation w/ Rosie Bailey, Nibble
-
43:21
L19: Top Data Science Algorithms | Lesson 19 | Data Science Series | Coding Ninjas
-
05:33
What is Data Science | Data Science Tutorial in 5 Mins | Data Science for Beginners | Edureka
-
1:30:45
ML ACADÉMIE FORMATION E-COMMERCE EN LIGNE, ENTREPRENDRE, GESTION PAGE, FRELENCE & COACHING WEBINAIRE
-
01:06

DESACTIVER Facebook RENCONTRE, comment mettre en pause son profil ou un compte Facebook Dating
-
13:35
Tuto Complet #3 - Les Projections D'Hosoda (Avec Ichimoku)
-
18:53

Un Business Ultra Rentable à Lancer en Afrique : Gagne 1 750 000 FCFA Par Mois
-
09:14

MLM/LA PROSPECTION TRADITIONNELLE M'A RUINE ET ET EPUISE DANS MON MLM
Commentaires